本篇文章给大家带来了关于python的相关知识,其中主要介绍了关于简历筛选的相关问题,包括了定义 ReadDoc 类用以读取 word 文件以及定义 search_word 函数用以筛选的相关内容,下面一起来看一下,希望对大家有帮助。

推荐学习:python视频教程
简历筛选
简历相关信息如下:

定义 ReadDoc 类用以读取 word 文件
已知条件:
想要查找包含指定关键字的简历(比如 Python、Java)
实现思路:
批量读取每一个 word 文件(通过 glob 获取 word 信息),将他们的所有可读内容获取,并通过关键字方式筛选,拿到目标简历地址。
这里有个需要注意的地方就是,并不是所有的 "简历" 都是以段落的形式呈现的,比如从 "猎聘" 网下载下来的简历就是 "表格形式" 的,而 "boss" 上下载的简历就是 "段落形式" 的,这里再进行读取的时候需要注意下,我们做的演示脚本练习就是 "表格形式" 的。
这里的话,我们就可以专门定义一个 "ReadDoc" 的类,里面定义两个函数,分别用于读取 "段落" 和 "表格" 。
实操案例脚本如下:
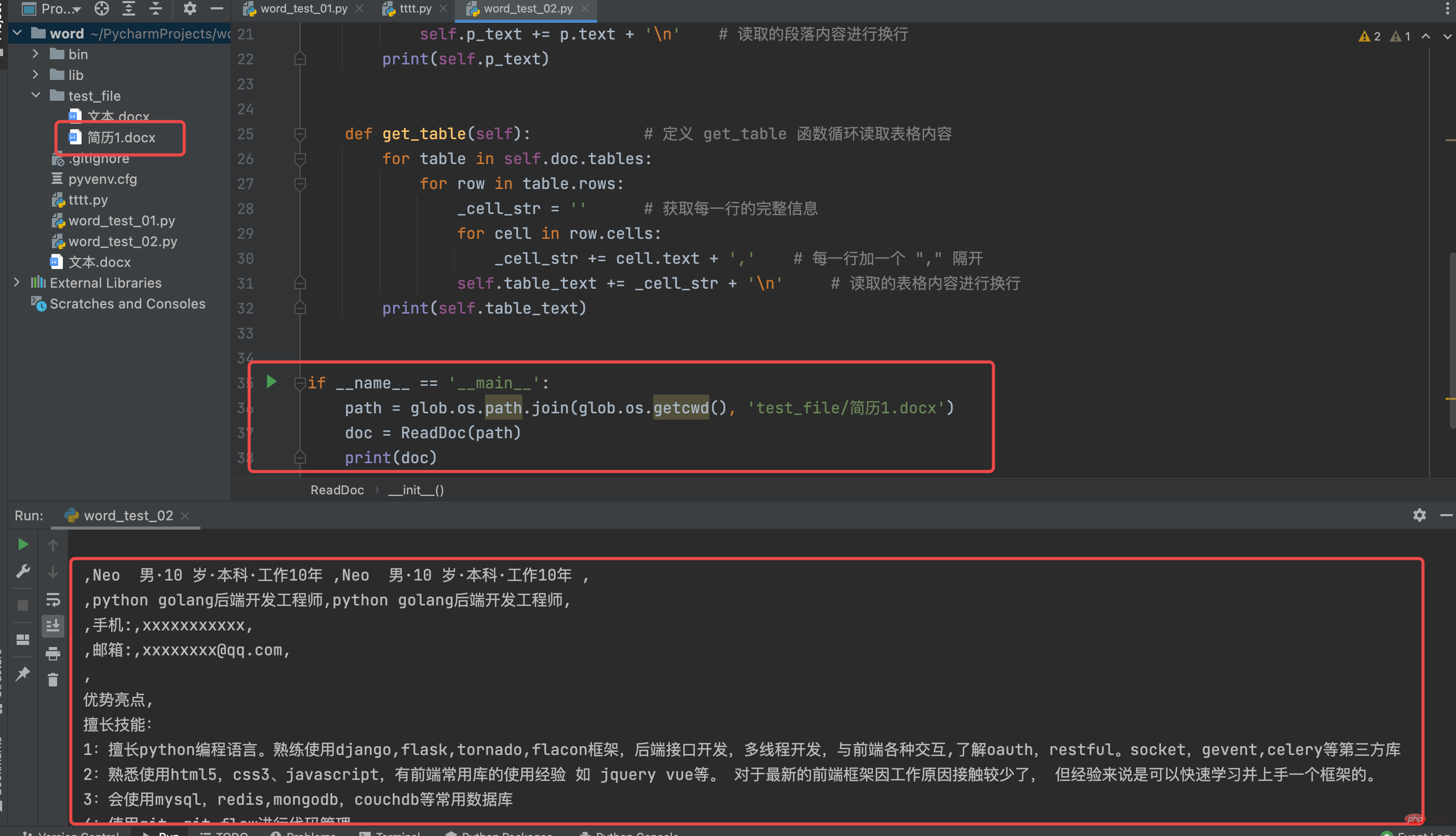
# coding:utf-8from docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件 def __init__(self, path): # 构造函数默认传入读取 word 文件的路径 self.doc = Document(path) self.p_text = '' self.table_text = '' self.get_para() self.get_table() def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落 for p in self.doc.paragraphs: self.p_text += p.text + 'n' # 读取的段落内容进行换行 print(self.p_text) def get_table(self): # 定义 get_table 函数循环读取表格内容 for table in self.doc.tables: for row in table.rows: _cell_str = '' # 获取每一行的完整信息 for cell in row.cells: _cell_str += cell.text + ',' # 每一行加一个 "," 隔开 self.table_text += _cell_str + 'n' # 读取的表格内容进行换行 print(self.table_text)if __name__ == '__main__': path = glob.os.path.join(glob.os.getcwd(), 'test_file/简历1.docx') doc = ReadDoc(path) print(doc)
看一下 ReadDoc 类的运行结果
定义 search_word 函数用以筛选 word 文件内容符合想要的简历
OK,上文已经成功读取了简历的 word 文档,接下来我们要将读取到的内容通过帅选关键字信息的方式,过滤出包含有关键字的简历。
实操案例脚本如下:
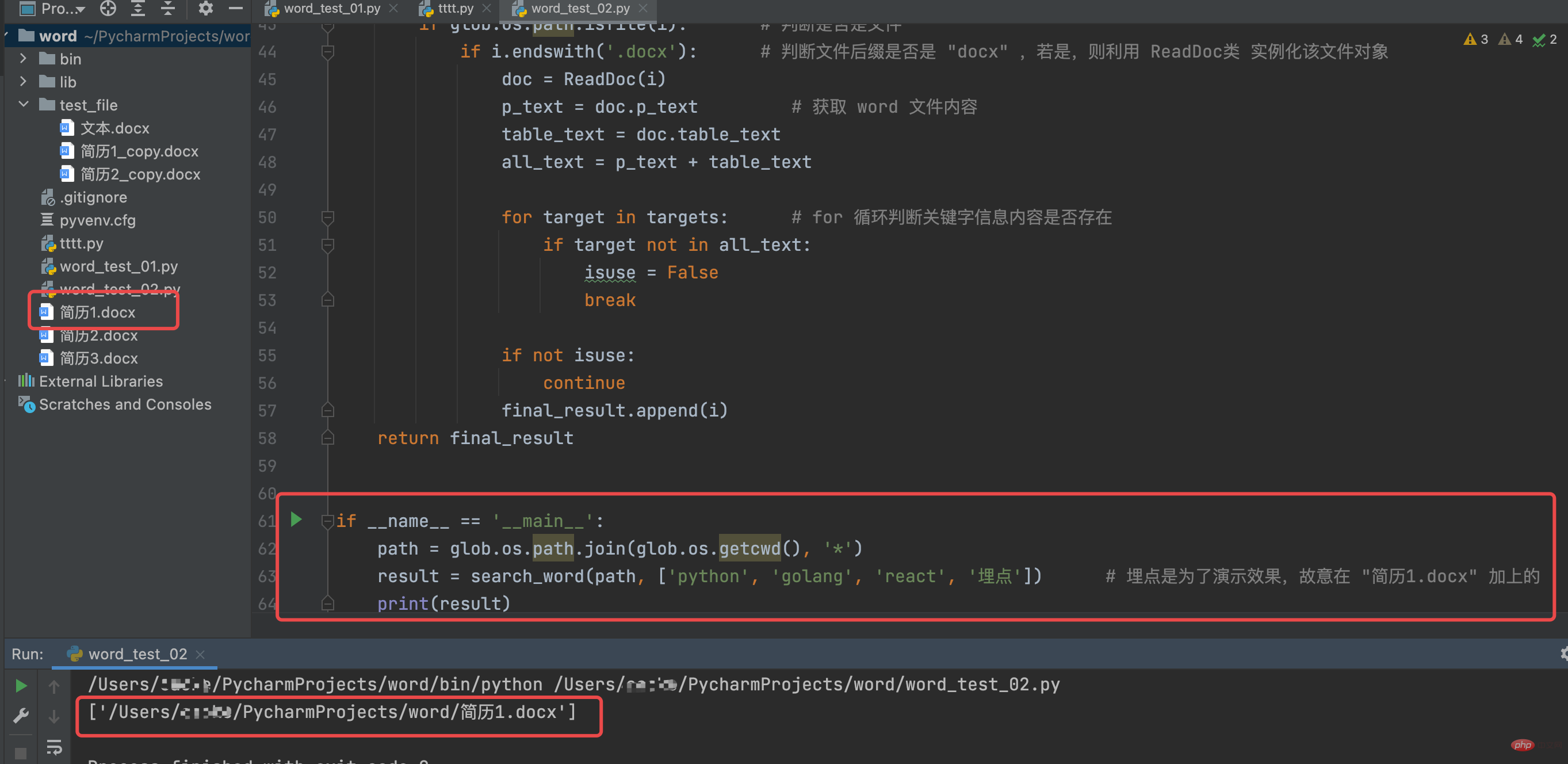
# coding:utf-8import globfrom docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件 def __init__(self, path): # 构造函数默认传入读取 word 文件的路径 self.doc = Document(path) self.p_text = '' self.table_text = '' self.get_para() self.get_table() def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落 for p in self.doc.paragraphs: self.p_text += p.text + 'n' # 读取的段落内容进行换行 # print(self.p_text) # 调试打印输出 word 文件的段落内容 def get_table(self): # 定义 get_table 函数循环读取表格内容 for table in self.doc.tables: for row in table.rows: _cell_str = '' # 获取每一行的完整信息 for cell in row.cells: _cell_str += cell.text + ',' # 每一行加一个 "," 隔开 self.table_text += _cell_str + 'n' # 读取的表格内容进行换行 # print(self.table_text) # 调试打印输出 word 文件的表格内容def search_word(path, targets): # 定义 search_word 用以筛选符合内容的简历;传入 path 与 targets(targets 为列表) result = glob.glob(path) final_result = [] # 定义一个空列表,用以后续存储文件的信息 for i in result: # for 循环获取 result 内容 isuse = True # 是否可用 if glob.os.path.isfile(i): # 判断是否是文件 if i.endswith('.docx'): # 判断文件后缀是否是 "docx" ,若是,则利用 ReadDoc类 实例化该文件对象 doc = ReadDoc(i) p_text = doc.p_text # 获取 word 文件内容 table_text = doc.table_text all_text = p_text + table_text for target in targets: # for 循环判断关键字信息内容是否存在 if target not in all_text: isuse = False break if not isuse: continue final_result.append(i) return final_resultif __name__ == '__main__': path = glob.os.path.join(glob.os.getcwd(), '*') result = search_word(path, ['python', 'golang', 'react', '埋点']) # 埋点是为了演示效果,故意在 "简历1.docx" 加上的 print(result)
运行结果如下:
推荐学习:python视频教程
